
Distributed systems are used in organizations for collecting, accessing, and manipulating large volumes of data. Recently, distributed systems have become an integral component of various organizations as an exponential increase in data is witnessed across industries.
With the advent of big data technologies, many challenges in dealing with large datasets have been addressed. But in a typical data processing scenario, when a data set is too large to be processed by a single machine or when a single machine may not contain the data to respond to user queries, it requires the processing power of multiple machines. These scenarios are becoming increasingly complex as many applications, devices, and social platforms need data in an organization, and this is where distributed data processing methods are best implemented.
Know more about Indium’s capabilities on Databricks and how it can help transform your business
Click Here
Understanding Distributed Data Processing
Distributed data processing consists of a large volume of data that flows through variable sources into the system. There are various layers in that system that manage this data ingestion process.
At first, the data collection and preparation layer collects the data from different sources, which is further processed by the system. However, we know that any data gathered from external sources are mainly raw data such as text, images, audio, and forms. Therefore, the preparation layer is responsible for converting the data into a usable and standard format for analytical purposes.
Meanwhile, the data storage layer primarily handles data streaming in real-time for performing analytics with the help of in-memory distributed caches for storing and managing data. Similarly, if the data is required to be processed in the conventional approach, then batch processing is performed across distributed databases, effectively handling big data.
Next is the data processing layer, which can be considered the logical layer that processes the data. This layer allows various machine learning solutions and models for performing predictive, descriptive analytics to derive meaningful business insights. Finally, there is the data visualization layer consisting of dashboards that allows visualization of the data and reports after performing different analytics using graphs and charts for better interpretation of the results.
In the quest to find new approaches to distribute processing power, application programs, and data, distributed data engineering solutions is adopted to enable the distribution of applications and data among various interconnected sites to complement the increasing need for information in the organizations. However, an organization may opt for a centralized or a decentralized data processing system, depending on their requirements.
Benefits of Distributed Data Processing
The critical benefit of processing data within a distributed environment is the ease at which tasks can be completed with significantly lesser time as data is accessible from multiple machines that execute the tasks parallelly instead of a single machine running requests in a queue.
As the data is processed faster, it is a cost-effective approach for businesses, and running workloads in a distributed environment meets crucial aspects of scalability and availability in today’s fast-paced environment. In addition, since data is replicated across the clusters, there is less likelihood of data loss.
Challeges of Distributed Data Processing
The entire process of setting up and working with a distributed system is complex.
With large enterprises compromised data security, coordination problems, occasional performance bottlenecks due to non-performing terminals in the system and even high costs of maintenances are seen as major issues.
How is Databricks Platform Used for Distributed Data Processing?
The cloud data platforms Databricks Lakehouse helps to perform analytical queries, and there is a provision of Databricks SQL for working with business intelligence and analytical tasks atop the data lakes. Analysts can query data sets using standard SQL and have great features for integrating business intelligence tools like Tableau. At the same time, the Databricks platform allows working with different workloads encompassing machine learning, data storage, data processing, and streaming analytics in real time.
The immediate benefit of a Databricks architecture is enabling seamless connections to applications and effective cluster management. Additionally, using databricks provides a simplified setup and maintenance of the clusters, which makes it easy for developers to create the ETL pipelines. These ETL pipelines ensure data availability in real-time across the organization leading to better collaborative efforts among cross-functional teams.
With the Databricks Lakehouse platform, it is now easy to ingest and transform batch and streaming data leading to reliable production workflows. Moreover, Databricks ensure clusters scale and terminate automatically as per the usage. Since the data ingestion process is simplified, all analytical solutions, AI, and other streaming applications can be operated from a single place.
Likewise, automated ETL processing is provided to ensure raw data is immediately transformed to be readily available for analytics and AI applications. Not only the data transformation but automating ETL processing allows for efficient task orchestration, error handling, recovery, and performance optimization. Orchestration enables developers to work with diverse workloads, and the data bricks workflow can be accessed with a host of features using the dashboard, improving tracking and monitoring of performance and jobs in the pipeline. This approach continuously monitors performance, data quality, and reliability metrics from various perspectives.
In addition, Databricks offers a data processing engine compatible with Apache Spark APIs that speeds up the work by automatically scaling multiple nodes. Another critical aspect of this Databricks platform is enabling governance of all the data and AI-based applications with a single model for discovering, accessing, and securing data sharing across cloud platforms.
Similarly, there is support for Datbricks SQL within the Databricks Lakehouse, a serveless data warehouse capable of running any SQL and business intelligence applications at scale.
Databricks Services From Indium:
With deep expertise in Databricks Lakehouse, Advanced Analytics & Data Products, Indium Software provides wide range of services to help our clients’ business needs. Indium’s propreitory solution accelerator iBriX is a packaged combination of AI/ML use cases, custom scripts, reusable libraries, processes, policies, optimization techniques, performance management with various levels of automation including standard operational procedures and best practices.
To know more about iBriX and the services we offer, write to [email protected].








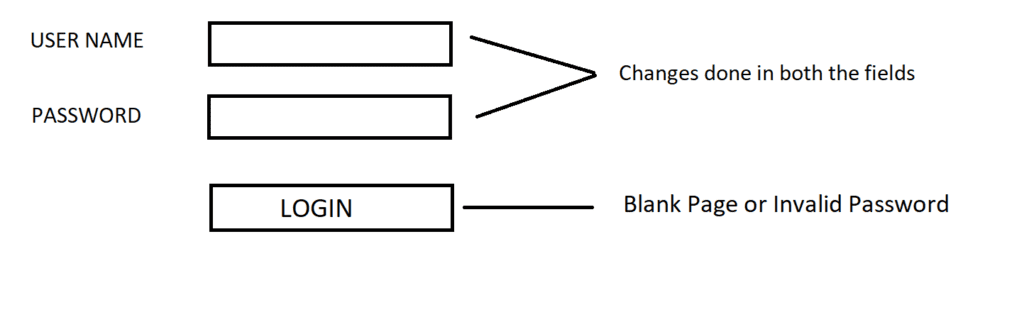
 Full Regression Testing
Full Regression Testing Real-Time Example of Regression Testing
Real-Time Example of Regression Testing







