Introduction
Apache NiFi supports robust and scalable directed graphs of data routing, transformation and NiFi is based on technology before called “Niagara Files” that was in development and used at scale within the NSA for the last 8 years and was made stable to the Apache Software Foundation through the NSA Technology Transfer Program.
Its main features are:
- User Friendly Web UI
- At runtime we can change routes
- Flexible configurable
Some of the use cases include, but are not limited to:
Apache Nifi we use to automate the process and it is more reliable and secure way to collect data from Source to destination. To overcome real time benchmarks such as limited or expensive bandwidth while getting data quality and reliability. Everything that happens to data is monitored by the users.
Cutting edge Big Data Engineering Services at your Finger Tips
Read More
Concept
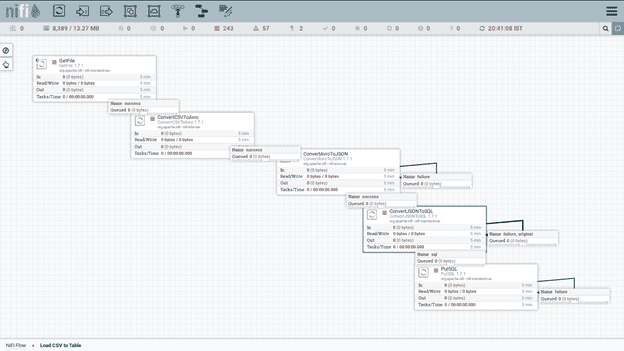
Let’s look at a simple ETL task like reading data from Local, converting character set and uploading to the database.
GetFile Processor:
- GetFile Processor we can able to fetch the data from local System Using Input Directory
- We need to define the location of file in Input Directory .So that GetFile Processor Fetch the data from that source location and passes into next Downstream Processor

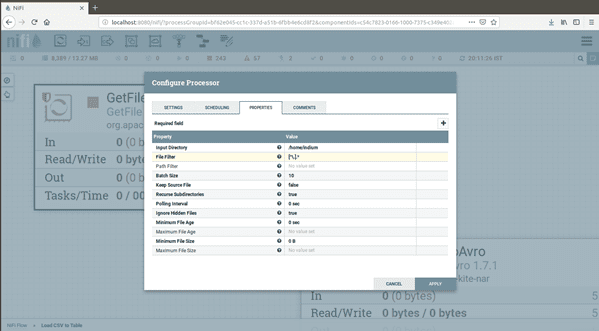
- We can Filter the file from Source Using File Filter

ConvertCSVToAvro Processor:
In UpStream Processor we fetch CSV file .Here we convert the CSV File Format into Avro Format.Conversion will happen in ConvertCSVToAvro Processor

ConvertAvroToJson Processor
Once we convert CsvToAvro then we need to convert once again like Json Format. Using ConvertAvroToJson Processor will convert the Avro schema into Json File Format. We can do some customization as well (optional).

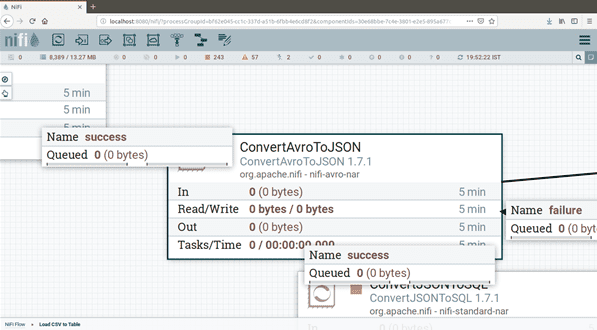
ConvertJSONToSQL
Now finally we get Json File. Now we have to import the flowfile into respective databases using ConvertJsonToSQL

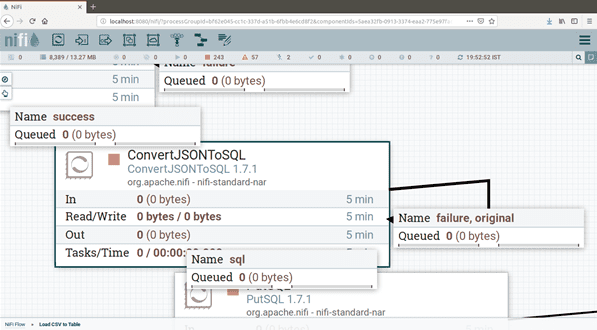
Incoming FlowFile is Entire Json File Format .
Parameters listed below:
JDBC Connection Pool:
Databases Connection (whatever databases you want to connect)
Statement Type: INSERT ,UPDATE,DELETE
Table name: Respective table name
Schema Name: Optional


Leverge your Biggest Asset Data
Inquire Now
PutSQL
Finally Execute statement in Putsql. We have to connect respective databases and load data from local to database. PutSql Processor is to load flowfile into Databases.

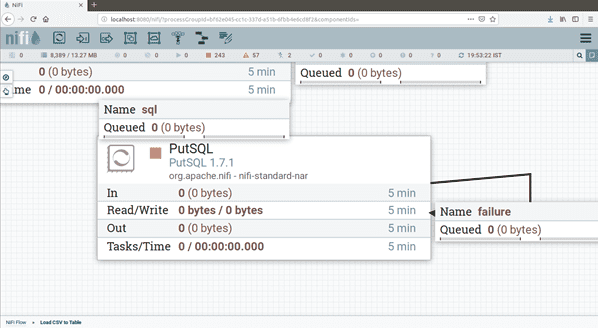
Overall Workflow: